自go1.7+,我们可以在编译时开启对有潜在slice越界访问风险的语句进行提示。
1 | package main |
此处代码并未对slice的使用进行边界校验,容易发生危险,因为 s []int 尺寸未知。
1 | go build -gcflags="-d=ssa/check_bce/debug=1" main.go |
当我们把上面的代码修改为:
1 | func f1(s []int) { |
再执行刚才的命令,就不会再提示有越界的可能了
原文地址(需梯子):
自go1.7+,我们可以在编译时开启对有潜在slice越界访问风险的语句进行提示。
1 | package main |
此处代码并未对slice的使用进行边界校验,容易发生危险,因为 s []int 尺寸未知。
1 | go build -gcflags="-d=ssa/check_bce/debug=1" main.go |
当我们把上面的代码修改为:
1 | func f1(s []int) { |
再执行刚才的命令,就不会再提示有越界的可能了
原文地址(需梯子):
最近在研究用Go写一个自己的解释型语言,有一本书叫《Writing An Interpreter In Go》, 作者在讲解如何编写解释器的时候,都是从写一个_test.go开始的,也就是说作者习惯于先写单元测试,以测试驱动开发,其实这是一个非常好的习惯,不过,作者在写_test.go文件的时候,都是先假设这个结构体、函数已经存在了,并且没有把关键的对象抽象成接口,因此,作者在运行go test的时候,是无法完成测试的,因为连编译都过不了,必须一边完善代码,一边重复运行go test,一直到完成开发。
基于这种开发模式下,其实我更期望能有一个Mock实现,写测试代码的时候畅通无阻,即使是没有实现,也能把各个测试用例覆盖到,当真实的实现完成后,我们只需要把mock实现替换成真实的实现就好了。
这么做还带来另一个好处,如果公司有SDET岗位,则可以直接让测试人员编写单元测试,开发任务和测试任务可以并行。
昨天闲着没事逛了逛 https://github.com/golang, 发现了一个非常有意思的框架: gomock, 官方的描述是,这是一个mocking framework, 在使用上也很简单,大致的步骤如下:
1、定义一个待实现的接口.
1 | type MyInterface interface { |
2、使用mockgen生成mock代码.
3、测试:
1 | func TestMyThing(t *testing.T) { |
看了这个步骤,想必大家应该猜到了,mocking framework 使用的是根据你的接口定义来自动生成一个Mock实现,我们还可以往这个实现里注入数据。
我们可以通过 .EXPECT() 为这个mock对象注入期望值
1 | mockObj.EXPECT().SomeMethod(4, "blah") |
1 | mockObj.SomeMethod(4, "blah") |
1 | mockObj.SomeMethod(5, "bldah") // 此处调用时直接会抛出错误 |
对于参数类型的期望,在调用这个Mock函数的时候会直接抛错异常
.EXPECT() 同样可以为某个函数注入返回值
1 | mockObj.EXPECT().GetSomething().Return("haha") |
1 | if "haha" == mockObj.GetSomething() { |
1 | if "haha" == mockObj.GetSomething() { |
功能强的还不止这个,如果我们在测试一个循环,希望的是每次调用 GetSomething() 都返回不同的值,该怎么办?
答案很简单,依次调用
1 | gomock.InOrder( |
接下来,让我们来实战一下吧。
我们以《Writing An Interpreter In Go》这本书中的 monkey 语言的 lexer 作为例子
我们看一下 monkey 的目录结构:
1 | monkey> tree . |
1 | type Lexer interface { |
lexer的功能很简单,每次调用NextToken(),都是返回下一个TokenToken的结构1
2
3
4
5
6type TokenType string
type Token struct {
Type TokenType // 类型
Literal string // 内容
}
比如下面的go语句
1 | var a = 1 |
lexter 在调用三次NextToken()后会得到三个Token, 依次是:
1 | Token{VAR, var} |
其实测试方法就是:给定一段代码,用Lexer解析后,能得到指定顺序的Token,而gomock是完全可以实现的。
1 | go get github.com/golang/mock/gomock |
1 | mockgen -source lexer.go -destination mock_lexer/mock_lexer.go |
input: 输入的语句
tokens: 期望的Token
1 | func getTestData() (input string, tokens []token.Token) { |
当然,这里我们没有实现,所以返回是nil
1 | func newMonkeyLexer(input string, excepts []token.Token, t *testing.T) (l Lexer, deferFN func()) { |
由于没写完真正的lexer, 那么我们就开始Mock吧
1 | func newMockLexer(input string, excepts []token.Token, t *testing.T) (l Lexer, deferFN func()) { |
为了方便在mock实例和真实实例之间进行切换,我们可以通过环境变量来控制当前的测试实例是什么,如果要使用mock进行测试,我们只需要在运行 go test 前执行:
1 | > export GO_MOCK_TEST=1 |
或
1 | > GO_MOCK_TEST=1 go test -v |
1 | func newLexer(input string, excepts []token.Token, t *testing.T) (l Lexer, deferFN func()) { |
以下是真正的测试代码,在没真实实现monkey lexer的情况下,我们可以写测试代码了,而且如果运行 go test -v 也是能通过的。
1 | func TestNextToken(t *testing.T) { |
1 | monkey> cd lexer |
1 | func newMonkeyLexer(input string, excepts []token.Token, t *testing.T) (l Lexer, deferFN func()) { |
我们将测试数据修改一下,假设 ten=666, 但不修改期望值,让测试报错
1 | input = ` |
再次运行测试
1 | monkey> cd lexer |
这里就报错了,说明我们的真实实例实现得有问题,需要修复这个BUG
gomock 的使用到这里就结束了,除了上面介绍到的一些功能,gomock 还有很多其他丰富的方法,大家可以去 GoDoc 获取更详细的接口信息。
欢迎关注我的微信公众账号: DeepIn-z
本人在一家互联网金融公司上班,对于一家互联网金融公司,最基本的功能就是客户入金和出金,而出金的稳定性是很重要的,出金不畅容易导致投资人恐慌,本文讲的是出金,出金接口我们对接的是招商银行的银企直联系统,那么银企直连系统是一个什么样的程序呢?
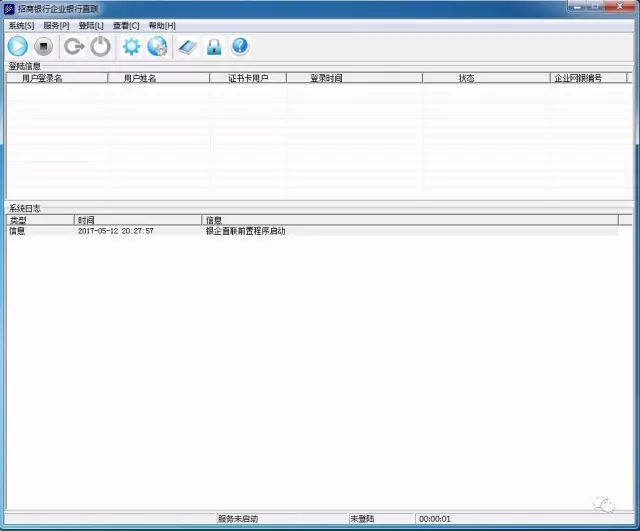
没错,这个程序是运行在Windows上的,并且需要插入USBKey才能正常工作,这就意味着,不能简单的使用命令行进行运维管理。
看到这里,做运维的同学的内心应该和我一样是崩溃的。。

跟大家解释一下,这个服务是做什么的,大家可以把这个程序当成是我们的业务系统和招商银行沟通的信使,所有出金操作、查询操作都是通过这个信使来完成。
由于各种未知的原因,比如网络不稳定,或者USBKey插入时间过长产生了一些莫名其妙的错误,那么就需要人工去重启一下服务或重新登录一下账号,而且,这个工作有时候是在夜间操作的,这相当于要24小时待命啊,虽然故障频率不高,但这根弦始终是崩着的,这简直就是在破坏我的幸福美好生活啊。

这种体力活的事情,我坚决不能干,所以一定要交给别人干。

别想多了,【别人】也只能是个外挂而已,谁都不喜欢干这种人肉体力活。
所以凭借着我18岁那年的开发经验,脑子里想到了 Windows 的消息模型,使用 SendMessage 给对应的窗体控件句柄发送特定的事件不就搞定了么,异常自动重启使用 CreateProcess 不就行了吗?
天真的我脑子里已经充满了 SendMessage 的语句
1 | LRESULT WINAPI SendMessage( |
有木有很熟悉的样子,惊不惊喜,开不开心?是不是感觉发送键盘点击事件、鼠标点击事件就OK了?
后面会讲到,其实还需要很多工作才能完成一个比较完善可用的外挂软件,
SendMessage基本上只能解决一部分问题
然而当我想完这些代码后,感觉还是太麻烦,因为按键精灵这类软件就能解决,为什么还要自己亲自操刀?不过最终放弃了这种念头,因为这是一个很重要的服务,说不定在未来会掌握好 几千个亿 的资金命运,如果安装了不明软件,资金安全如何得以保障???绝对不能这么草草的做这种决定,所以还是决定老老实实的撸代码了。。。
用什么语言是个问题,在Windows上可以使用 C++ , C# 系列,而且C#我记得有一个automation框架可以完成类似的操作,不过本人最近这3年一直在使用 golang,前两种语言目前也只是偶尔用用的节奏,所以基本处于手生的状态,而 golang 本身也支持使用 syscall 来调用 windows 的 DLL(动态链接库),所以果断使用 golang, 因为这个外挂大部分的WinAPI都在 user32.dll 和 kernel32.dll 里,我们只需要能加载这几个DLL 就可以调用强大的 WinAPI 了
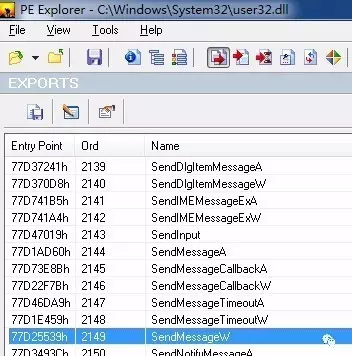
大家可以使用 PE Explorer 查看一个DLL有哪些输出函数
1 | var ( |
大家可以看到,在这里我们使用的是SendMessageW,而不是SendMessageA,因为go语言底层调用DLL接口时,传入的是utf16,看看下面的代码就明白了
1 | func SetWindowText(hwnd HWND, text string) { |
这是一个设置窗体标题的API,第一个参数是窗体句柄,第二个参数大家可以看到,是将go语言的字符串转换成UTF16格式,并获取其指针。
另外值得注意的是,如果我们编译出来的程序是32位的,那么尽量不要用来作为64位程序的外挂,因为有很多复杂一点的功能无法实现,后续会提到这个部分,银企直连 这个服务是32位的,因此我们的go语言也是安装的32位的,同时为了更好的编译测试,我的虚拟机装的是 Win2008 R2 32位 操作系统
那么我们应该如何向一个窗体发送消息呢?能不能先做实验,不写代码呢?答案是肯定的,我们先请出我们的神器,Spy++
将瞄准器拖拽到具体的窗口上,就会得到窗口的句柄,我们可以通过 FindWindowW 或 EnumChildWindows 来实现相同的功能
银企直连正常工作需要两个步骤
我们先看看启动HTTP监听按钮
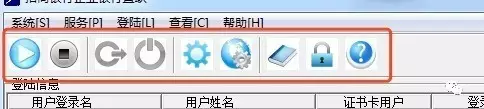
我们使用spy++抓到了这个ToolBar的句柄

然后用 spy++ 向第一个按钮发送鼠标点击事件,那么就可以开启监听了
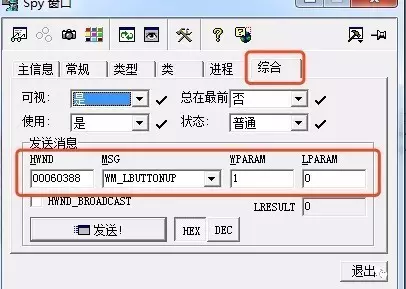
点击动作在Windows消息来看,是分为两个动作,一个是 WM_LBUTTONDOWN 而另一个是 WM_LBUTTONUP ,所以我们需要发送两次事件,当完成这两次发送后,我们可以看到下面的界面
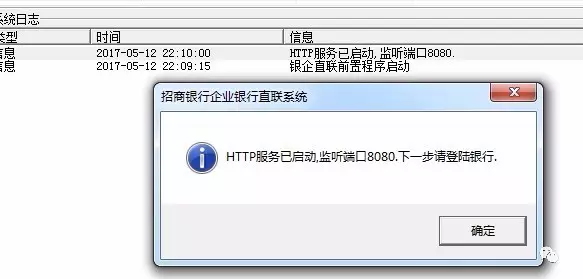
没错,其实这里是一个坑,启动监听还不好好启动,非得弹出一个消息框,同时伴随着的是spy++卡死了,为什么呢? 因为我们使用的是SendMessage,这是一个同步的过程,因为出现了消息框,所以spy++还未收到返回消息,所以就卡死了。当我们点击完 确认 按钮后就可以恢复了,当然我们也可以使用 PostMessage ,不过这个接口只适合不在乎执行结果的情况下执行。
好了,这里我们出现了第一个坑:有弹窗,我们的外挂需要自动识别,并且能够自动关闭弹窗。

OK, 我们继续,我们该开始登陆了

刚才我们 SendMessage 里的WPARAM是1,那么,这个按钮是4
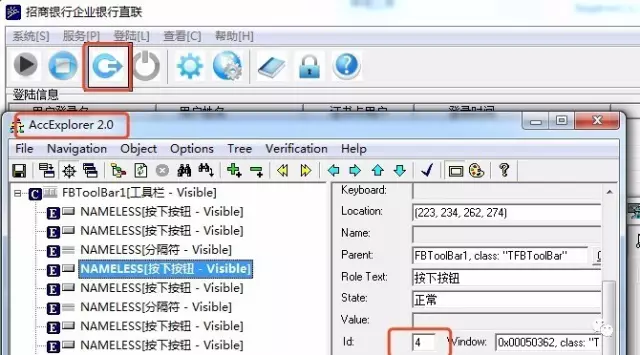
继续使用 spy++ 发送消息

模拟完发送,整个人一下子就不好了,因为这个按钮根本就没有反应,后面的两个参数你也不知道到底传什么好,就在陷入了整个困局的时候,发现我们其实可以通过快捷键 ctrl+b 完成监听, ctrl+i 进入登录界面
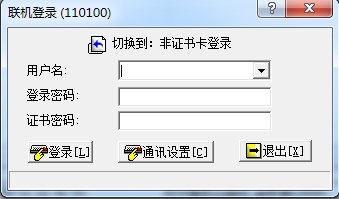
此时未插入USBKey
所以,我们需要使用另外一个API: SendInput, 包括后面的密码输入,也一样要使用这个API
我们看一下这个API的定义
1 | UINT WINAPI SendInput( |
看上去很心塞,一堆参数。

由于本文讲解的是调研篇,我们此处假设SendInput可以完成快捷键的按键模拟,密码输入的按键模拟,实际上这个API确实是可以工作的,因为这个接口是真实的模拟键盘输入,不针对某个窗口句柄。
接下来我们会迎来第二个坑,如果USBKey正常工作,那么用户名里的的内容是自动填写好的,如图:
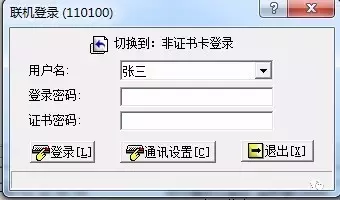
这个用户名是从USBKey里读出来的,读取是需要时间的,因此我们可以在这里不停的向这个文本框发送WM_GETTEXT 消息,拿到用户名,如果用户名是预期的数据,我们就认为此时USBKey是正常工作的,否则如果长时间用户名未成功加载,则说明USBKey工作异常,应该发送报警信息。
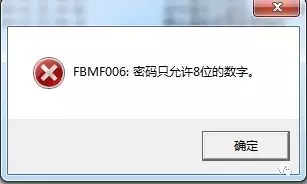
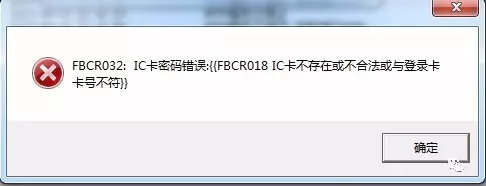
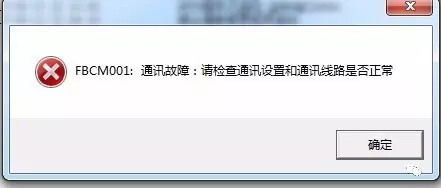
我们大概会得到如下几类错误
对于密码错误这个问题,我们的外挂应该立即停止工作,因为密码输入次数超过限制,USBKey将会锁定,公司出金服务就挂了。。。。

为什么会密码输入错误呢?因为很有可能在自动输入时,被其他程序干扰了一下
我们在代码中会尽量用SetForegroundWindow让窗口保持在最前面,成为激活状态
那么对于通讯故障,解决的办法就只能是重新尝试了
剩下的问题,我个人认为发出报警,人工处理一下会比较合适。
此时迎来两个新问题,
对于第一个问题,我们可以通过 EnumChildWindows 来遍历这个消息框的孩子句柄,然后通过 GetWindowText 就可以知道是什么内容了。
我们重点来讨论第二个问题
此处有两种解法:

登陆信息列表
为了提升难度,我们选择方案2

这种方法是比较困难的,有困难,我们要解决,没有困难我们也要创造困难来解决。。。。
为什么难呢?
因为我们没办法通过SendMessage 发送 WM_GETTEXT 事件获取内容,但是我们可以通过 LVM_GETITEMTEXT 来获取 listview 的列表内容
BUT….. 跨进程这么拿是拿不到的,同时,不同位数的进程,也是拿不到数据的。
如何解决?
我们需要使用API VirtualAllocEx 向银企直联进程申请一块内存空间,用于我们的外挂进程和银企直联进行数据沟通,当我们发送 LVM_GETITEMTEXT 消息之前,我们需要把参数信息写到这个内存块里,然后再使用SendMessage,ListView的数据会写到这个内存块,最后我们通过 ReadProcessMemory 来读取获取到列表的数据
这里就是为什么32位不能读64位程序的内容的原因了,虽然我们可以使用WriteProcessMemory 和 ReadProcessMemory 来写入和读取进程内存里的数据,但是由于通过这种机制进行交互,指针大小是不同的,通过SendMessage指令虽然能执行成功,但是回写的数据内容会跑飞。
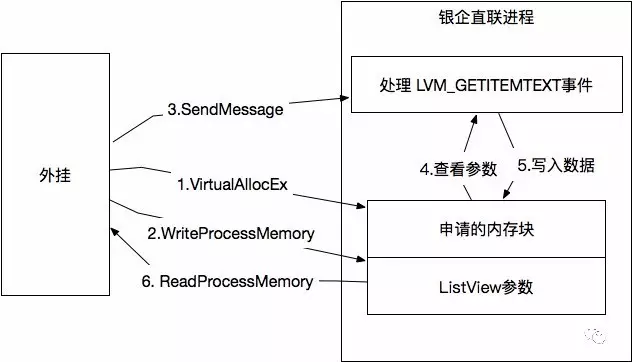
箭头代表数据流向,所有的API调用都是在外挂这边完成的
整个流程大概就是这样的,我们需要借助远程进程的内存块来做数据交互,但最后切记一定要使用VirtualFreeEx 释放掉不用的内存块。
此处应该有总结:
SendMessage到此为止,关键的技术内容我们已经调研完了,下一篇内容我们会讲如何使用go语言实现一个真正可用的外挂。
我们先来预览几个外挂的截图吧:
外挂工作中…..
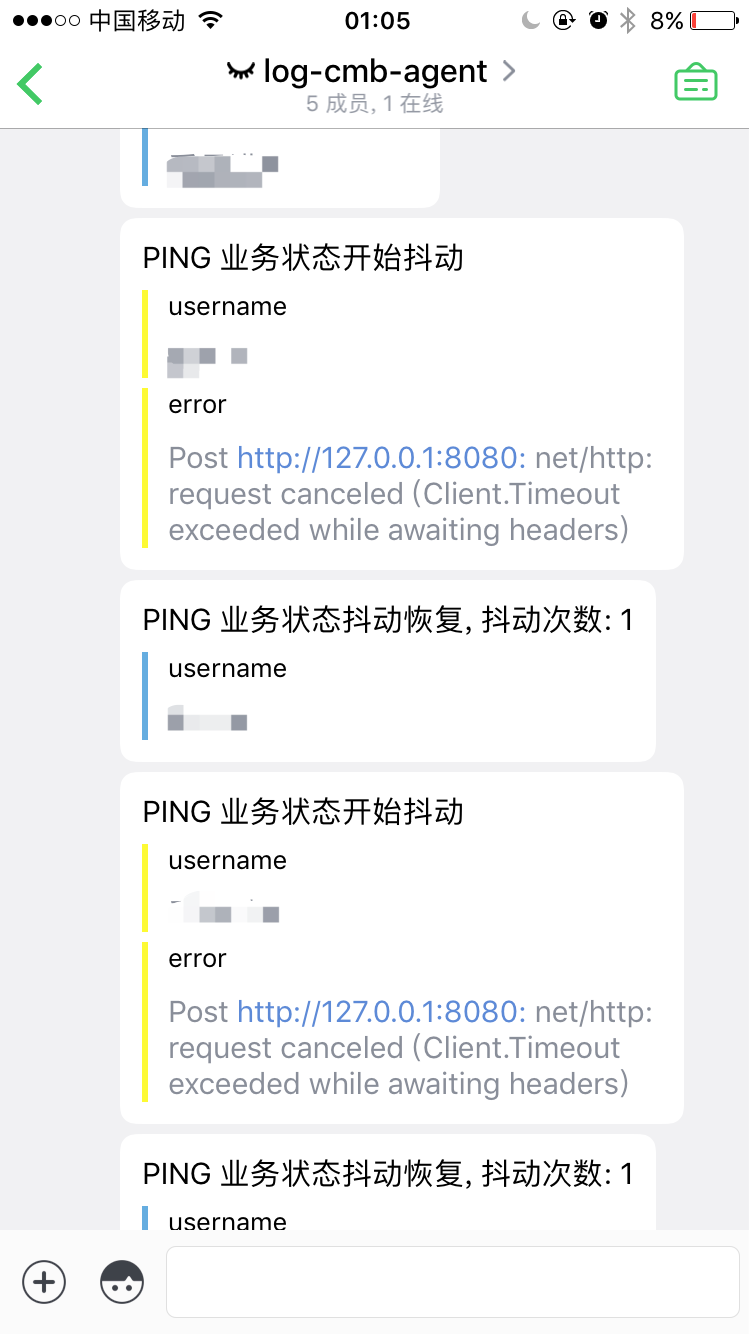
当发生稳定性异常时,会通过bearychat的Incoming服务发送报警
欢迎关注我的微信公众号:DeepIn-z

目前官方支持的Transport
Transport的作用
1 | type Message struct { |
目前支持的协议
服务底层的协议格式
1 | type Message struct { |
Transport不支持,因为传输层是需要进行数据序列化和反序列化的,同时节点通讯其实是Transport的Client和Server进行通讯。(Server部分可以使用martini, gin, echo 等框架实现,但是他们同属于HTTP范畴,所以可以认定为相同的Transport)
Micro 服务是基于 Transport 进行的,Transport 可以有多种实现方式,例如 RabbitMQ,NSQ,HTTP,NTATS……,由于不同的Transport有自己的协议,例如HTTP的协议我们基本可以认为他会分为 Header 和 Body 两个部分,因此,HTTP Transport 的实现就会把请求里的HTTP Request Header 作为 Message 里的 Header, Body 也直接从请求里获取,也就正好填充了 Message 这个结构体,Micro Server 根据 Header 里的 Content-Type 来确定使用哪一种 Codec 来进行解码,目前只有JSON和 ProtoBuf,Codec 的作用是将Body里的数据解码到具体的服务的协议。
在开发中,我们需要面对各种各样的环境,开发环境、测试环境、生产环境……
并且,各个环境的参数和配置各不相同,比如数据库连接,服务器配置等。我们怎样在不同环境中调用正确的配置?
这是一种常见的思路,通过创建多个配置文件,但根据命名区分,比如开发环境为develop-app.conf,测试环境为testing-app.conf,生产环境为production-app.conf
我们通过在系统中设置环境变量export ENV_MODE=develop等等。在读取配置文件时,根据环境变量读取响应的配置文件。
这个方式易于使用,深得大家喜爱。但这个方案在集群扩大的一定程度时,会遇到一下几个主要问题:
对于这些问题,我们认为配置应该集中化管理。
集中化管理带来以下好处:
最简单的方案就是存储在redis中。KV的存储方式天然适合关联配置文件。但要完整的使用整个方案,需要做一些准备。
我们的基本思路是:将配置文件的值替换为占位符,在系统启动时,相应的工具将根据占位符到redis中查询到实际的值,替换回配置文件。
最初的配置文件是这样:
1 | { |
现在我们的配置文件变成了这样:
1 | { |
在启动时,我们通过这个工具:https://github.com/gogap/env_json
这样读取配置文件
1 | func main() { |
这个工具,默认从/etv/env_string.conf读取redis的配置信息,当然你可以更改,更多细节参看说明文档。
在这个过程中,env_json首先会从/etv/env_string.conf读取到redis的配置信息。
典型的/etv/env_string.conf内容如下
1 | { |
连接上redis后,以上面的例子来说,将执行hget global.mysql host以及hget global.mysql port,将取到的值通过模板替换,更新到配置文件中,得到一个正常的json文本,剩下的就是通过json库把json内容解码到结构体中。
到目前为止,我们实现了从redis中读取并替换配置,那么我们写入配置的时候呢?
假如我们有数十个服务,我们难道需要逐个去redis中设置吗?我们怎样把这个流程自动化?
我们需要另一个工具:env_sync
我们存储配置文件其实是一个具体的git工程,比如开发环境是develop_env,生产环境是production_env,开发人员都可以编辑develop_env这个工程,少数人可以编辑production_env。
工程里的内容什么呢?
我们约定了这样的目录结构
1 | develop_env |
在工程中,有一系列的文件夹,文件夹中有一个叫data的文件。这样的目录结构会被env_sync识别到,并转化成一系列的redis命令。
假如global.mysql文件夹下的data文件内容是
1 | { |
转化出来的命令是:
1 | hset global.mysql host 127.0.0.1 |
此过程与读取过程正好相反,同样的,env_sync也是从/etc/env_strings.conf读取配置信息。与读取工具保持了统一。
整体来看我们需要做几个工作
为各个环境维护一个配置文件project
安装env_sync,便于同步配置文件到redis
设置/etc/env_strings.conf
更改读取配置文件的代码,兼容env_json
再结合自动化部署工具,每次配置文件有更新时,我们就在线上环境自动同步到redis。
还有一种需求时,配置文件会动态变化,而我们不想重启服务就读取到配置文件,那你需要https://github.com/gogap/redconf
这个工具可以实现对redis中数据的检测,如果数据发生变化,会触发回调,应用可以得到变化前后的值。
这篇文章【不是翻译】,是讨论我们团队在实际开发和运维过程中,怎样基于gitlab的CI系统和supervisor,进行微服务的自动化部署。
持续集成的重要性不用多说,能够显著提高开发、部署和运维效率,但非侵入式的持续集成架构是很难的,此处分享我们在小型的开发团队中采用的持续集成方案。
我们采用自建gitlab进行代码版本管理,通过docker进行搭建极其容易。目前的gitlab CI系统已经非常完善,可以针对特定的代码分支执行持续集成任务。
怎样安装gitlab-ci-runner参考这篇文章
测试环境采用supervisor进行进程监控,保证应用挂掉之后能重启,且能正常的杀掉老的进程。
以目前实现的一个监控组件monitor作为示例,分享怎样实现持续集成。
monitor是一个标准的micro服务,假设代码存放目录为
1 | $GOPATH/src/git.domain.com/micro/monitor |
monitor的代码目录如下
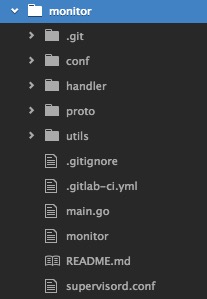
其中与部署相关的是两个文件
.gitlab-ci.yml是一个名字固定的文件,gitlab会根据这个文件名,来找到这个文件,将其中的内容根据分支设定,发送给runner执行,比如我们的文件内容是:
1 | develop: |
注意,文件里的GOPATH是一个变量,这个变量在gitlab后台的monitor工程中设置,它是全局的,不用每个工程都设置,在某个工程设置一次即可。
具体参考这篇文章
`supervisord.conf是supervisor的配置文件,supervisor的安装等等内容请参考官网
内容如下:
1 | [program:monitor] |
内容很简单,就是进去某个设定好的目录,执行某个命令。
实际效果:
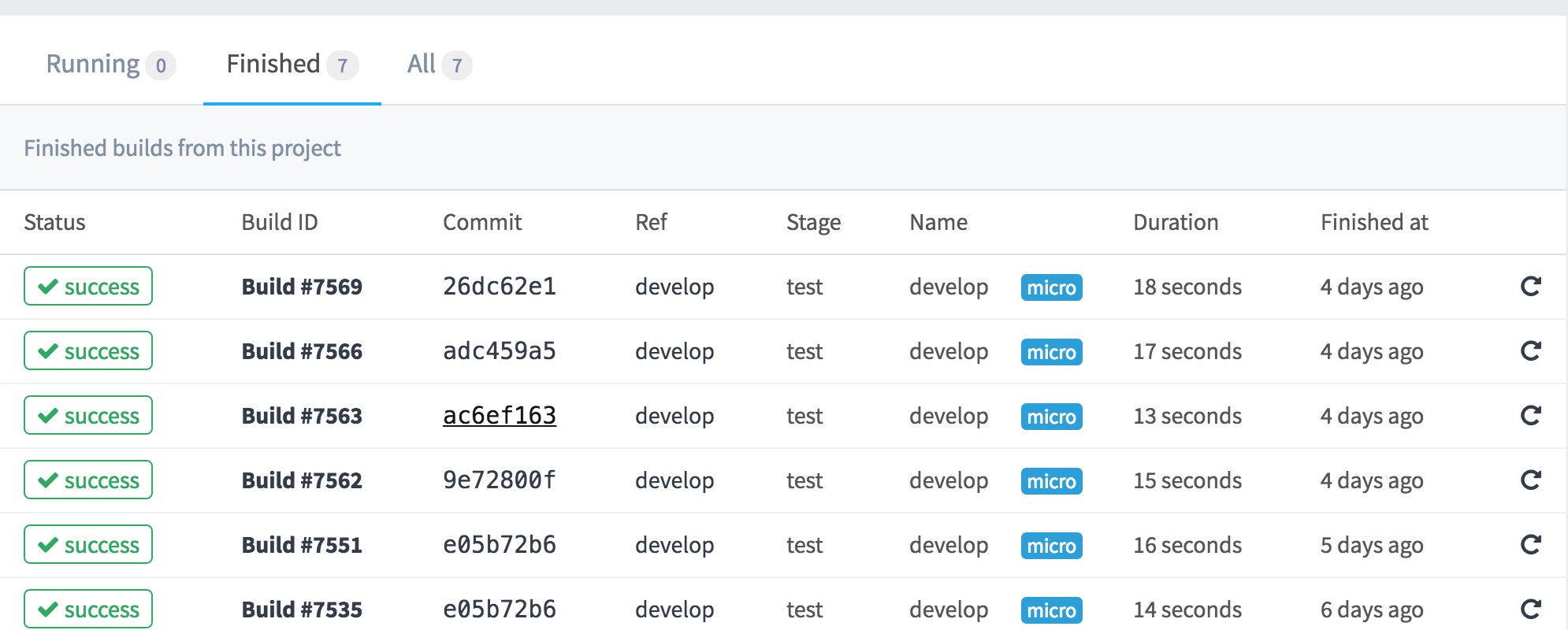
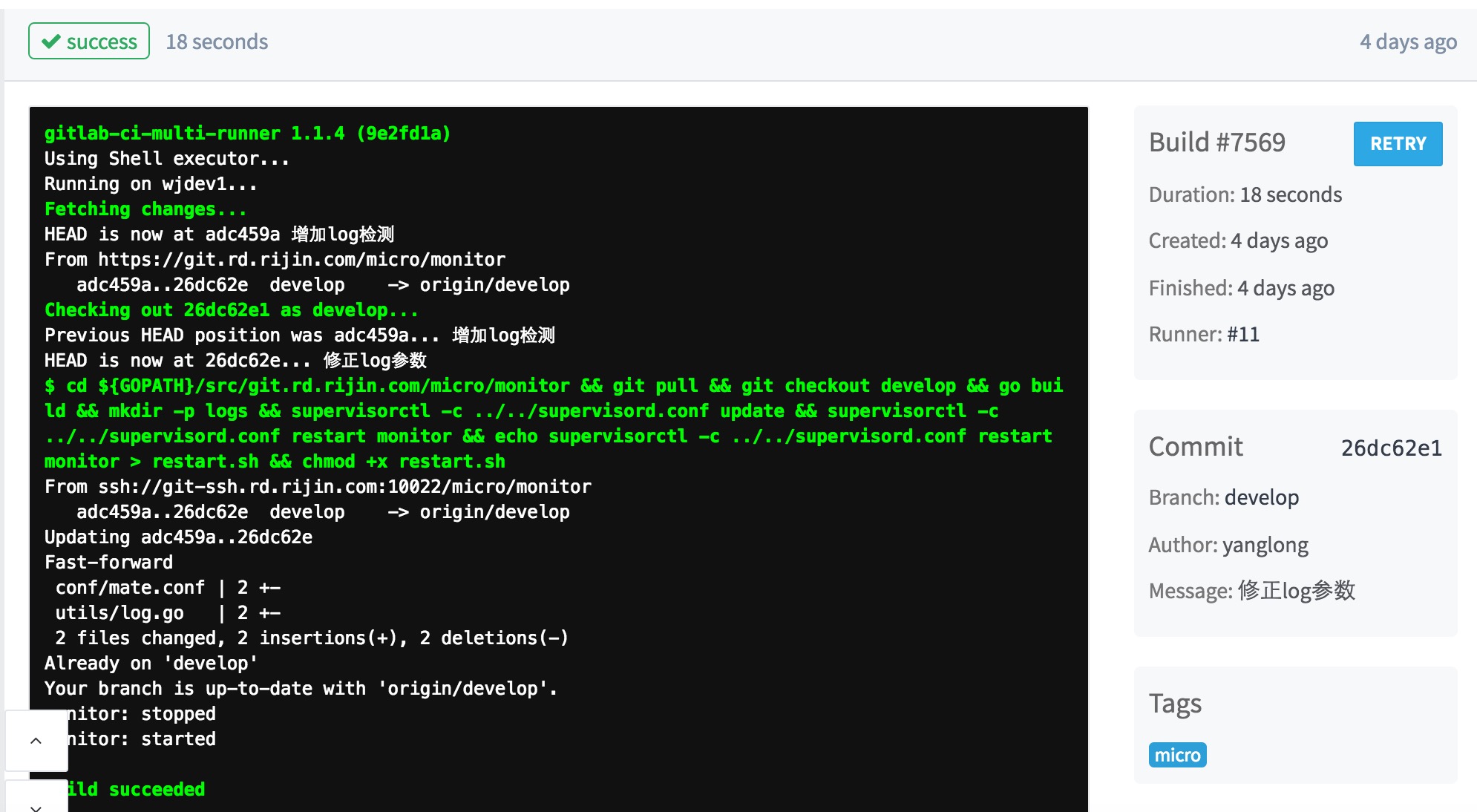
本质上就是gitlab+supervisor的组合,需要一些细节的设计,开发的项目需要增加两个文件。部署的服务器需要设计好路径结构,否则可能会找不到文件。实际操作过程中有疑问欢迎给我发邮件。自动化部署如果想要运行起来,还需要另一个方面的配合 — 不同环境的配置文件问题,本地环境、开发环境、测试环境、生产环境的配置大部分情况下都不一样,怎样智能的读取响应环境的配置文件?这个问题我们也有自己的解决方案,在接下来的文章中我会进一步说明。
这篇文件简单介绍,怎样安装使用gitlab-ci-runner,执行持续集成任务。
gitlab-ci-runner是gitlab官方出品的持续集成工具,简单来说就是当你的代码触发了某个持续集成任务,运行在主机上的gitlab-ci-runner就会执行预先设计好的脚本。比如我们设计好,某个项目的develop分支有更新时,发送一段脚本到runner,这段事先写好的脚本,主要工作是进入这个项目的目录,git pull,编译,重启。这样就你只是推送了代码,但已经实现了简单的自动化部署。
官方的安装文档在这里,非常简单,因为runner是采用golang编写的,所以你本质上只是下载了一个可执行文件,没有任何依赖项。按照你的平台选择即可:
https://gitlab.com/gitlab-org/gitlab-ci-multi-runner
不必多说。
注:gitlab-ci-multi-runner和gitlab-ci-runner就是一个东西,两个名字而已。
安装好以后,运行起来的效果应该类似这样
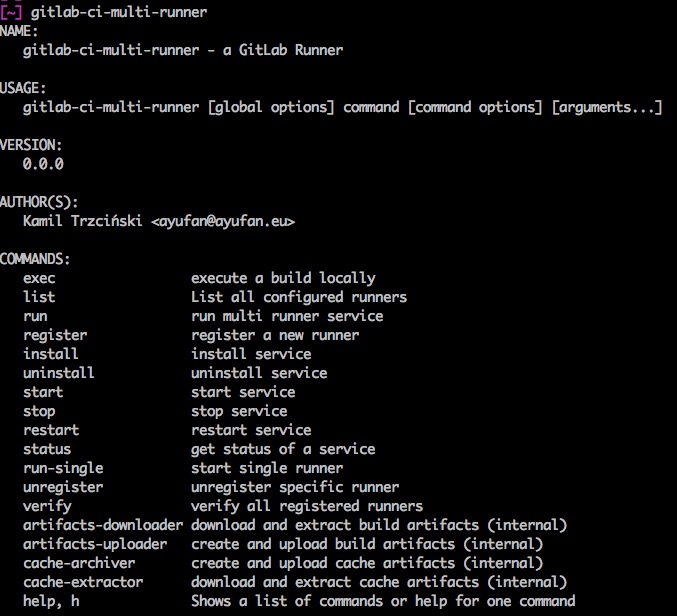
注意,接下来的命令不要使用sudo,在linux环境下,如果使用sudo,在执行任务时会带来权限上的问题。
接下来执行gitlab-ci-multi-runner register,进入交互式的页面,依次输入各个参数即可
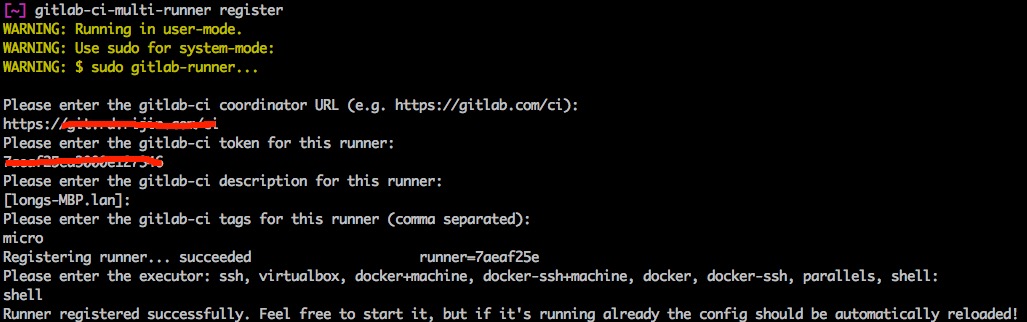
执行gitlab-ci-multi-runner verify
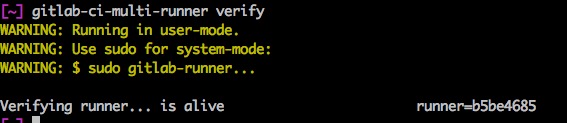
执行gitlab-ci-multi-runner run &
此时runner就已经运行起来,等待着gitlab发送任务。
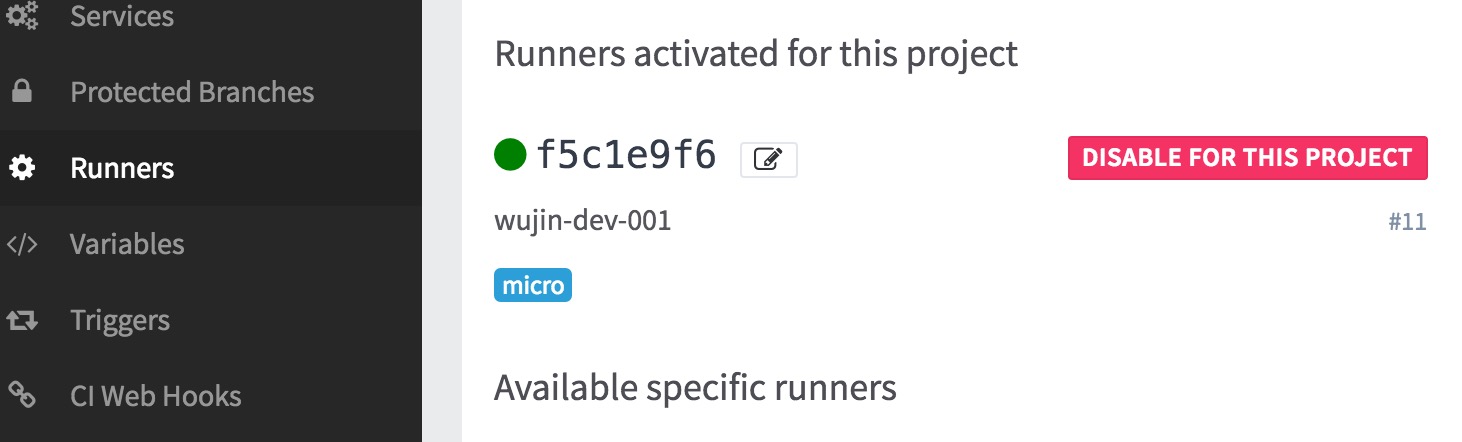
此时在gitlab后台的runner页面中应该可以看到绑定成功的runner

在gitlab进入某个需要进行持续集成的项目目录,setting > runners
为这个项目绑定runner,ENABLE FOR THIS PROJECT
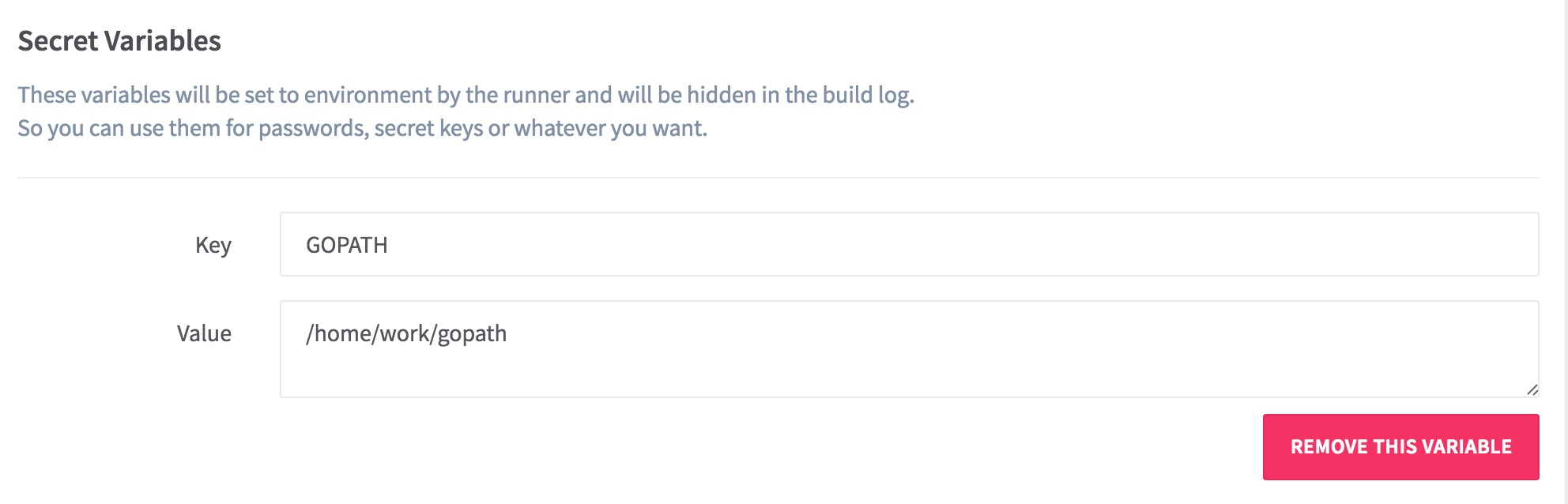
在某个项目的setting > variables中,设置全局变量,注意这里设置的变量,所有项目都可以读取到。
这篇文章是Dave Cheney在2014年发表的,我认为在go语言的接口设计上,这篇文章起到了指明灯的作用,包括Micro在内的框架,都使用了这种方式提供API。原文看这里
正文开始:
下面的内容是我的一次演示的文字版本,这是我在dotGo上演讲的『Functional options for friendly APIs』,在这里已经编辑的可读了。

我想用一个故事作为开头。
在2014年的晚些时候,你的公司发布了一款革命性的分布式社交网络工具,很明智的,你选择了Go来开发你的产品。
你分配到的任务是编写极为重要的服务端组件,看起来可能像这样
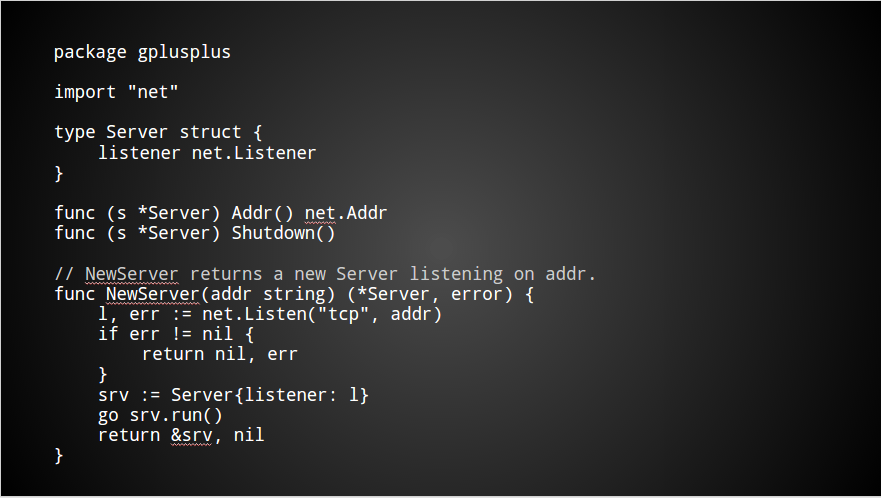
这里有一些不可导出的字段需要初始化,通过一个goroutine运行起来,响应请求。
这个包有很简单的API,非常容易使用。
但有一个问题,当你发布了你的第一个版本后,新的需求不断的被提出来。

手机客户端经常是响应的很慢,甚至停止响应。你需要添加支持来对慢的客户端主动断开连接。
为了增加安全,新的需求是增加安全连接(TLS)。
然后,你的某些用户是在一个很小的服务器上运行服务,他们需要限制客户端数量的方式。
下面是想要对并发数进行限制。
不断的新需求…
限制你需要调整你的API来满足这一系列的新需求

还需要考虑不同版本直接接口的兼容性问题。
实话说,谁用过这样的API?
谁编写过这样的API?
谁的代码以为依赖了这样的包,而不能正常使用了?
明显的这种解决方式是笨重而脆弱的,同时也不容易发现问题。
你的包的新用户,不知道哪些参数是可选的,哪些是必须的。
比如说,如果我想创建一个服务的实例作为测试,我需要提供一个真实的TLS证书吗,如果不需要,我需要在接口中提供什么?
如果我不关心最大连接数,或者最大并发数,我应该在参数中设置什么值,我应该使用0?0听起来是合理的,但这依赖于具体的接口是怎样实现的,这也许真的会导致并发数限制为0。
在我看来,这样写API是容易的,同时你把正确使用接口的责任抛给了使用者。
这个例子甚至代码写的很糟糕,文档也不友好,我想这示范了一个看起来华丽,其实很脆弱的API设计。
现在我们定位了问题,我们看看解决方案。

与其提供一个单独的接口处理多种情况,一种解决方案是提供一系列的接口。
用户按需调用即可。
但你很快会发现,提供如此大量的接口,很快会让你不堪重负。
让我们看看另一种方式。
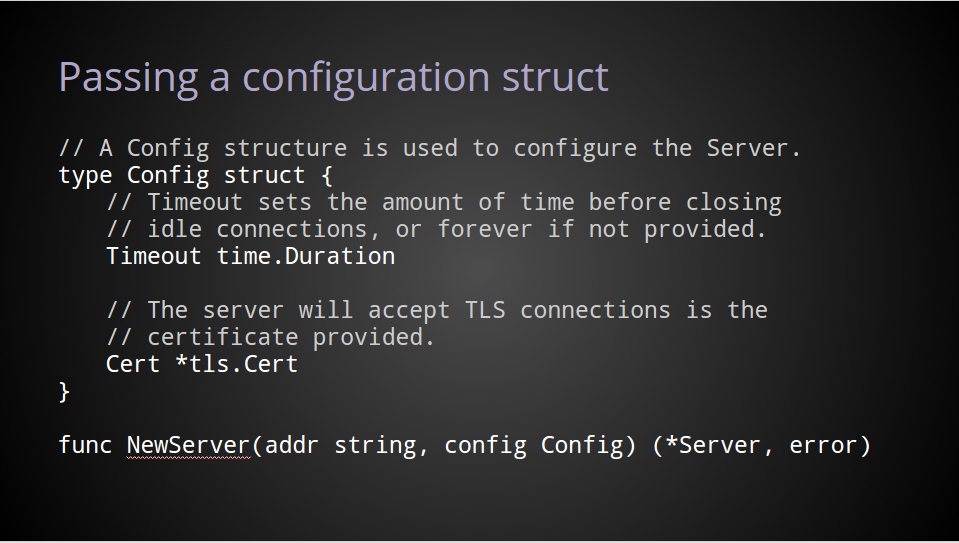
一种非常简单的方式是提供一个配置结构体。
这有一些优势。
使用这种方式,如果有新的需求加入,在结构体中增加选项即可。对外的公共API仍然保持不变。这也能让文档更加友好、可读。
在结构体上注明这是NewServer的参数,文档上也很容易识别。
潜在的它也允许用户使用0作为参数的值。
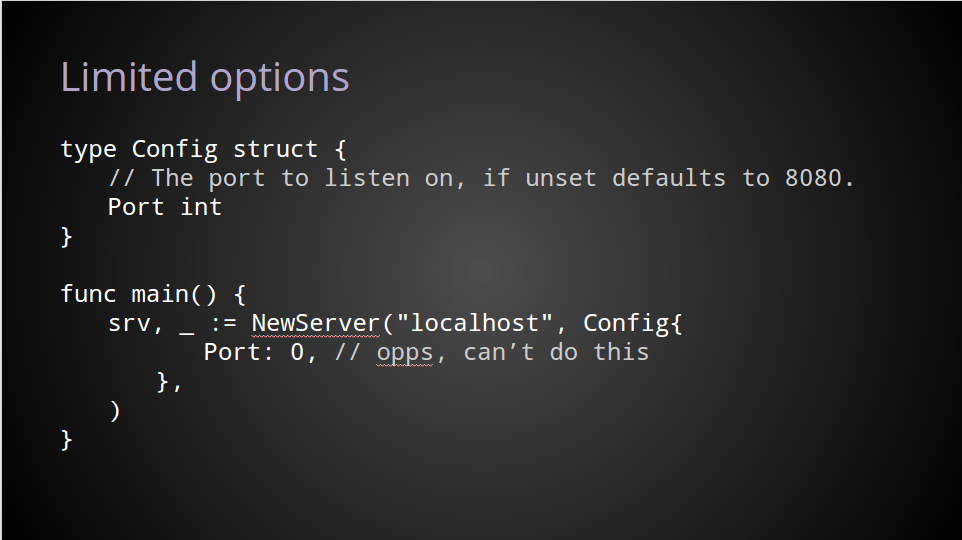
但是这种模式并不完美。
对于默认值是有歧义的,特别是0的值如果有特别的含义。
比如在这里的配置结构中,如果port没有被设置,NewServer会监听8080端口。
但是这有一个负面影响,你也许想设置为0,然后服务端默认分配一个随机端口,但你设置的0与默认值是相同的。

大部分时候,你的API用户只是想使用你的默认值。
即使他们不想改变你的配置的任何内容,仍然不得不传入一些参数。
当你的用户读你的测试代码或者示例代码时,在想着怎样使用你的包,他们会看到这个魔幻的空字符串参数。
对我来说,这让我感觉很糟糕。
为什么你的API的用户需要传入一个空的值,只是简单的让你的函数满足声明需求?
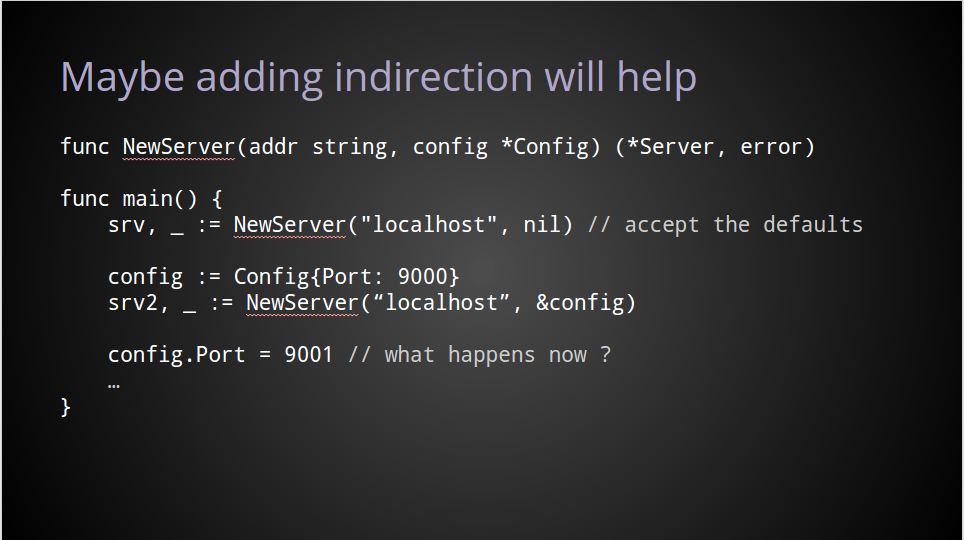
一个常见的解决办法是传入一个结构体指针,这让调用者可以传入nil,而不用考虑空值的问题。
在我看来,这个方案有前面的示例中的所有问题,甚至让问题更复杂了。
首先,我们仍然需要在第二个参数传入点什么,但目前,这个参数可以是nil了,而且大部分时候,对于默认的使用者,它就是nil。
使用指针的方式,包的作者和使用者都会担心的是,他们引用了同一份数据,随时有可能在运行中这份数据被修改而发生突变。
我想设计精良的API不应该要求用户传递这些额外的参数,只是为了应对一些罕见的情况。
我认为我们,Go程序员,应该努力确保不要求用户传递一个nil作为参数。
如果我们想要传递配置信息时,这应该是自解释的,尽量的有表达性。
现在,我们怀着这样的理念,我讨论一下我认为更好的解决方案。
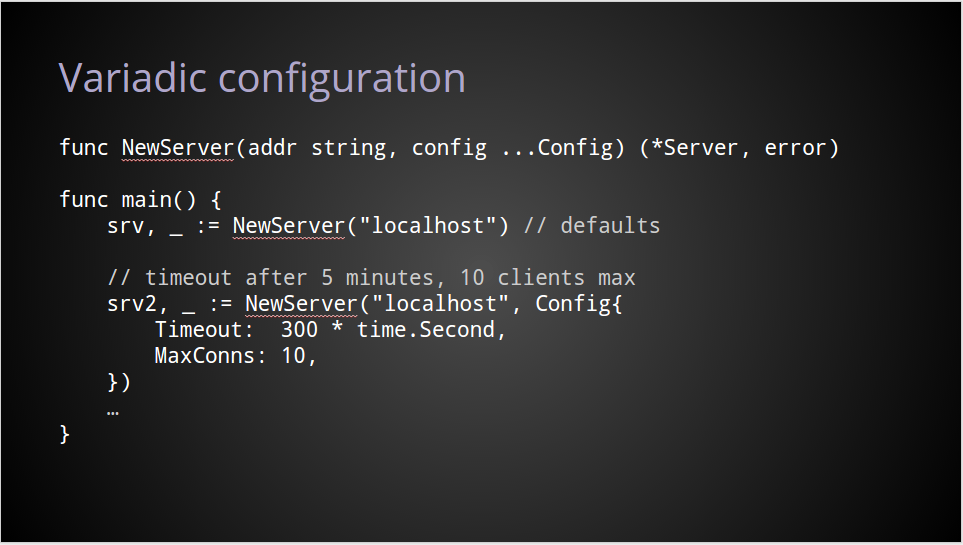
我们可以让API把不必须的参数作为一个变参。
不是传入nil,或者一些值为0的结构体,这种函数的设计发出了这样的信号:你不需要在config上传入任何参数。
在我看来这解决了两个问题。
首先,默认的调用方式变得简介命了。
其次,NewServer现在只接受config的值,不是指针,移除了nil和其他可能的参数,确保用户不会修改已经传入的参数。
我认为这个一个巨大的提升。
但我们深究一下,这仍然有问题。
明显对你的预期是提供最多一个config值,但这个参数是变参,实现的时候需要考虑用户传入多个参数的情况。
我们可以既能使用变参,同时也能提高我们的参数的表达性吗?
我认为这就是结局方案。
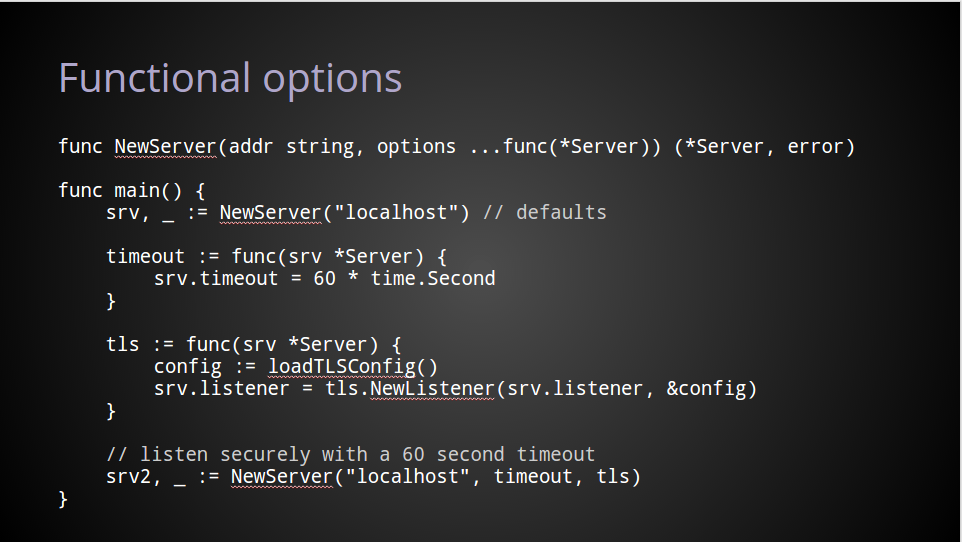
在这里我想要说清楚,函数式参数的想法是来自于Rob Pike的这篇文章:Self referential functions and design ,我鼓励每个人都去看看。
这种方式与上面的例子关键的不同在于,服务的定制化并不是通过传递参数实现的,而是通过函数来直接修改server的配置本身。
正如前面看到的,不传递变参让我们使用默认的方式。
当需要进行配置时,我们传递一个操作server的配置的函数。
上面的代码中,timeout这个函数是用于改变server的配置中的timeout字段。
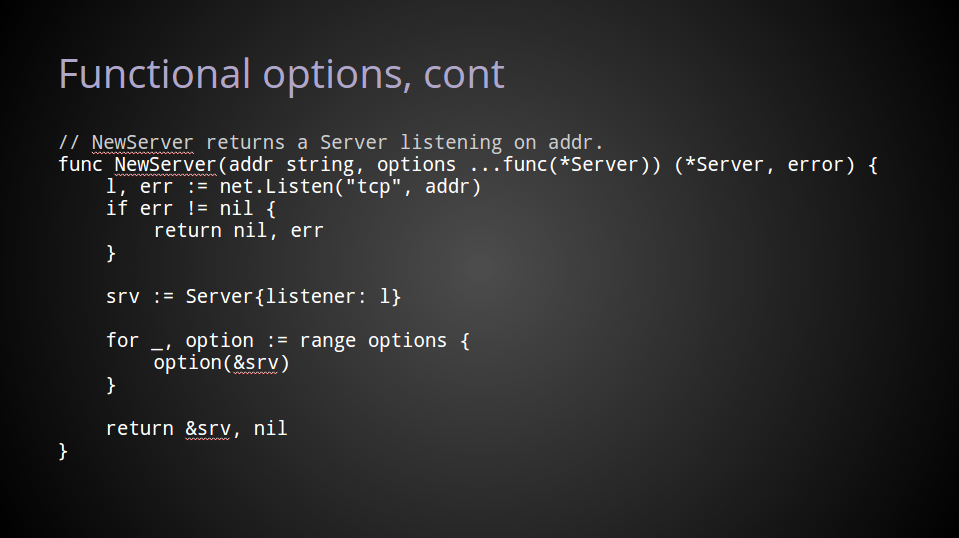
在NewServer的实现内部,直接应用这些函数即可。
在上面的代码中,我们调用了一个net.Listener,在server的示例中,我们使用了这个默认的listener。
然后,对于每个传入的option,我们都调用它,把我们的配置传入进去。
很明显,如果没有option传递进来,我们就使用的是默认的server.
使用这种方式,我们可以让API有这样的特性
全文完。
Micro在几乎所有接口中使用了这样的方式,比如要创建一个micro server的实例,开发者通过一个option.go提供了所有可能的配置函数,当然你也可以自己实现。
这是一系列介绍Micro框架的文章的第七篇,我将会把作者的博客翻译成中文,推广Micro这个微服务框架。
自发表上篇文章以来,已经有一段时间了,但我们仍然努力在为Micro添砖加瓦,现在确实需要还债了,让我们一次解决掉。
如果你想先了解一下 Micro工具箱,阅读以前的文章即可。
构建分布式系统是很有挑战性的,这毫无疑问。虽然我们已经解决了很多工程上的问题,我们仍然重复的在构建许多模块。目前,由于我们开始了更高级别的抽象,虚拟机到容器技术,适应新的语言,作用于云计算,都对微服务提出了要求。总有一些事情需要我们不断的去学习,怎样构建高性能的、高容错的系统仍然是下一波的技术浪潮。
重复与创新之间的战争从未停止,但我们需要做一些事情,通过云计算、容器技术、微服务来缓解我们的痛苦。
我们为什么这样做?为什么我们持续的重新构建同样的模块,为什么我们持续的尝试解决大规模、容错性和分布式系统的问题?
我脑海中出现的是『bigger, stronger, faster』,或者是『speed, scale, agility』,你可能经常从C级别的管理人员口中听到这个说法。但关键的是,确实存在这样的需求,需要我们构建更加高性能和要弹性的系统。
在互联网的早期,只有数千或者数万用户在线,随着时间的推移,我们看到开始加速,现在我们面对的是数十亿用户和数十亿的设备。我们需要学习怎样为目前的情况构建系统。
上一代的人也许记得C10K problem,我不确定我们现在处在什么阶段,但我想我们现在谈论的是百万级的并发。世界上最大的技术公司,在10年前就已经解决了这个问题,也有了模式来构建这样大规模的系统。但剩下的其他人仍然在学习。
像Amazon,Google,Microsoft现在提供给我们的云计算平台,对大规模部署是有益的。但我们仍然努力在搞清楚,怎样编写应用程序,可以高效的利用这些大规模的资源。你也许这些天听说了容器的编排,微服务、云计算很多了。工作在很多层面上推进着,当我们完全确定了我们的模式,确定了需要解决的问题,我们的Micro就能作为工业级的产品发布了,这还需要一段时间。
许多公司现在求助的问题是『我该怎样构建可扩展的、高容错的系统?』但目前对这些重要的问题,有帮助的回答是很少的。
我该怎样编写可扩展的、高容错的系统?
Micro看起来通过专注于微服务的必要的软件开发工具,定位了问题。我们会详细的谈谈怎样帮助你构建有弹性的、高容错的系统,我们从client端开始。
客户端在go-micro中是用于发起请求的模块,如果你已经构建过微服务挥着SOA架构,你会知道重要的一部分时间和执行过程是花在调用其他服务获取相关信息上面。
然而在巨大的应用中,关注点主要在接受请求返回内容,在微服务世界中,更像是取回或者发布内容。
这里是精简过的go-micro中client的接口,有最重要的三个方法Call, Publish 和 Stream。
1 | type Client interface { |
1 | type Request interface { |
Call和Stream是用来做同步通信请求,Call返回一个单一的结果,而Stream是一个双向的流式连接,与另一个服务维持着,其中任何消息都可以发进来也可以发出去。Publish用于发布异步的消息,通过broker,但我们今天不讨论它。
客户端是怎样工作的,前面的文章已经讨论过了。翻看以前的文章即可。
我们只是特别的讨论一些重要的内部细节。
客户端使用RPC层,结合broker,codec,register,selector和transport来提供丰富的组合。分层的架构非常重要,所以我们可以把单个的组件进行分离,减少了整体的复杂性,也提供了插件化的能力。
客户端本质上抽象了与服务端之间的有弹性的、高容错的通信过程。像另一个服务发起请求看起来是非常直接的,但有几种情况是可能潜在的发生失败的。
下面我们开始了解这些功能和他们是怎样运作的。
在分布式系统中,服务因为各种原因会频繁的加入和脱离集群。网络隔离、机器故障、调度等等。我们并不真正想关心它们。
当我们像另一个服务发起请求,我们通过名字识别服务,并允许客户端通过服务发现获取到服务的一系列实例,得到各个实例的地址和端口。服务在启动时在服务发现中心进行注册,在退出时进行注销。

正如我们提到的,任何类型的问题都会出现在分布式系统,服务发现也不例外。所以我们依赖于经过严格测试的分布式服务发现系统,例如consul、etcd和zookeeper,使用它们存储服务的信息。
它们都使用基于Paxos的Raft算法来进行网络选举,这解决了我们的一致性问题。通过运行一个3到5个节点的集群,我们可以容忍大部分的系统故障,为客户端提供稳定可靠的服务。
现在我们可靠的把服务名字解析到了一堆地址列表。我们怎样选择其中的一个进行调用呢?这就是go-micro中的selector发挥作用的地方。它基于register模块构建,提供负载均衡策略,比如轮询或者随机,也提供过滤、缓存和黑名单的功能。
这里是定义的接口:
1 | type Selector interface { |
当前的策略是非常简单直接的,当Selector被调用时,它从register获取到服务,然后创建一个Next函数,从节点池中选择出符合要求的节点。
客户端会调用这个Next函数,根据负载均衡策略,获取到下一个符合要求的节点,并发出请求。如果这个请求失败了,而且重试次数大于1,它会使用相同的程序,获取下一个节点,再次调用。
这里是有很多不同的策略的,比如轮询、随机、最少连接、权重等等。负载均衡策略对于分布式系统是必不可少的。
虽然有一个可靠的服务发现系统是很好的,但每次请求都去查询一次并不高效。如果你想象一个大规模的系统,每个服务都这样做,很容易就会使服务发现系统过载。这会让整个系统不可用。
为了避免这种情况,我们可以使用缓存。大部分的服务发现系统提供了一个监听更新的机制,一般来说叫做Watcher。不是去轮询服务发现系统,而是等待事件发送给我们。go-micro 的Registry提供了Watch的概念。
我们已经编写了一个带缓存的selector,它把服务缓存在内存中。如果缓存中不存在时,它会去服务发现系统查找,缓存,并用于之后的请求。如果watch事件收到了,缓存模块会与register进行更新。
首先,通过移除服务查找,大大的提高了性能。这也提供了一定的容错,万一服务发现系统宕机了呢?我们仍然有一点偏执,害怕缓存由于节点发生故障而被污染了,所以节点都维持着合适的TTL。
下面介绍一下黑名单,注意一下Selector的接口有Mark和Reset方法。我们不同真正的保证,注册进来的节点都是健康的,所以我们需要做黑名单。
任何一个请求发送之后,我们都会跟踪它的结果。如果这个服务的实例出现了多次失败,我们就可以大体上把这个节点加入黑名单,并过滤掉它。
节点在回到节点池之前会在黑名单中会存在一段时间,这是很严格的,如果这个节点失败了我们就需要移除掉它。这样我们可以持续的返回成功的请求,不会有任何延迟。
Adrian Cockroft最近开始讨论在微服务架构中消失的组件,其中一个有意思的是,传统的超时和重试策略导致了雪崩效应。我建议你看看这个演示。这个演示把问题总结的特别好。

Adrian 在上面描述的是一种常见的情况,一个缓慢的响应会导致超时,然后客户端会触发重试。这事实上是一个请求链路,这创造了一系列的新请求,而旧有的请求仍然在处理中。这样的配置失误会导致大量服务的过载,造成的调用失败是很难回滚的。
在微服务世界,我们需要重新想想,处理重试和超时的策略。Adrian继续讨论了潜在的解决方案。其中一种方式是超时之后,在新的节点上发起请求。

在重试的这方面,我们已经在Micro中使用了。重试的次数可以进行配置,如果你调用了一个失败的节点,客户端会在新的节点发起重试。
超时经常被深思熟虑,但事实上经常从传统的静态超时设置开始。直到Adrian演示了他的想法,超时策略变得很清晰了。
预算型超时策略现在也内置在Micro中,让我们看看它是怎样工作的。
第一个调用设置了超时,每个调用链上的请求都会消耗整体的超时时间。如果时间为0了,我们就会停止请求或重试,并返回调用链。
按照Adrian提到的,提供动态的预算型超时是非常好的,避免了不必要的雪崩。
更远一点来说,下一步应该是移除任何类型静态的超时。服务的响应时间根据环境的不同,请求的不同是不同的。这应该是动态的SLA,根据当前的状态进行调整,但这些事会留在未来解决。
连接池是构建可扩展系统的很重要部分,我们很快就看到了没有连接池的局限性,经常导致文件描述符数量达到限制,导致端口用尽。
目前有个进行中的PR为go-micro增加了连接池,由于Micro插件化的特性,把连接池放在transport的上层很重要,这样HTTP,NATS,RabbitMQ等等,都会受益。
你也许会想,这是特定实现的,一些transport也许已经支持了。这是对的,不能总是保证在不同的transport下工作效果是一样的。通过把这个放置于上层,我们减少了transport模块的复杂性。
确实有很多好用的东西是go-micro内置的,那么还有什么呢?我很高兴你这么问…
我们有这个功能,这个功能在前面的文章也讨论过了。服务包括名字和版本,注册在服务发现系统。当一个服务从注册器中查询出来时,它的节点是按照版本分组的。这样一样,selector就可以根据版本,进行流量负载。

当我们发布新版本时,这非常重要,它可以确保所有事情运作正常,这样才能把所有服务进行升级。新版本可以被部署到一个小型的节点上,客户端会自动的分发一定比例的请求到这个新的节点。通过结合一些编排系统比如Kubernetes,你可以非常有信心的部署,一旦有任何问题也可以回滚。
我们也有,selector是非常强大的,它有能力把过滤条件传递进去,对节点进行过滤。这在client端调用时可以传递参数。一些意见存在的过滤可以在这里看到,比如metadata,endpoint和版本过滤。
你也许有一些功能只在某些特定版本的服务上存在。需要将这些请求分发到这些特定版本的服务上。这是非常好的功能,特别是多个不同版本的服务在同时运行时。
另外一个有用的地方是,你想要根据地区对服务进行路由。通过设置数据中心的标签在服务上,你可以过滤出本地的节点。根据metadata进行过滤是非常强大的,希望有更多的应该能够把这个功能使用起来。
Micro原生的插件化架构是你一次又一次听到的。这从设计的第一天就已经确定了。这是非常重要的,Micro提供模块来构建整个系统。有时候的运行会超出控制,但这些都可以改善。
每个人对怎样构建分布式系统都有自己的想法,我们实际上是提供了一个方式,让人们能设计他们想要的解决方案。不仅如此,现在也有很多经过严格测试的工具,我们可以直接使用,而不是自己重写任何东西。
技术始终在进化,全新的、更好的工具每天都在出现。我们怎样避免止步不前,插件化的架构意味着我们可以使用目前的组件,未来也可以使用更好的组件进行替代。
每个go-micro的特性都被设计成golang中的接口,通过这样做,我们可以实际上替换底层的实现,这几乎不需要进行代码改动。在大部分情况下,只需要简单的引用这个包,然后在启动时加入参数就可以了。
在go-plugins有很多现成的插件可以使用。
go-micro目前提供了默认的consul作为服务发现系统,http作为transport,你也许会想要使用一些别的东西,或者实现自己的插件。我们已经有社区的贡献者分享了Kubernetes 的注册插件和Zookeeper的注册插件。
大部分时候,插件的使用类似这样:
1 | # Import the plugin |
1 | go run main.go --registry=etcd --registry_address=10.0.0.1:2379 |
如果你想要看更多的细节,参考之前讨论 Micro on NATS的文章。
客户端和服务端都支持中间件的概念,称为wrapper。通过支持中间件,我们可以增加在请求和返回的业务逻辑前面或者后面,添加自定义的逻辑。
中间件是很容易理解的概念,数以千计的库在使用它。在处理崩溃、限制并发、认证、日志、记录等场景下,很容易发现它的妙处。
1 | # Client Wrappers |
这里是一个很直接的插件
1 | import ( |
很容易对不对,我们发现很多公司在Micro上层,创建了自己的层级,用于初始化大部分默认的wrapper,所以所有的wrapper可以在同一个地方进行添加。
现在我们看看wrapper怎样让应用更有弹性,更能容错。
在SOA或者微服务世界,一个单独的请求可能会调用多个服务。大部分情况下,聚合许多信息返回给调用者。在成功的情况下,它运行的很好,但一旦发生错误,很容易触发雪崩式的错误,除了重启整个系统,很难恢复。
我们部分的解决了这个问题,通过在客户端使用重试机制和黑名单。但在一些情况下,我们需要组织客户端发起这个请求。
这里是circuit breaker怎样起作用的

circuit breakers的理念非常直接,方法的执行是根据对失败的情况进行监控而进行封装的。当失败的情况达到一个阈值时,breaker开始起作用,任何未来的调用尝试都会返回错误,而不会调用实际的业务函数。在超时时间过了以后,进入一个半开状态。如果某个请求失败了,breaker会再次生效,如果成功了就会恢复到正常。
虽然内部的Micro客户端有一些容错特性,但我们不应该依赖它来解决所有问题。在wrapper中使用circuit breakers让我们受益很多。
如果我们非常轻松的能响应世界上所有的请求,那就太好了,不过是在梦里。真实的世界不是这样工作的,执行一个查询需要消耗时间,资源的限制让我们只能响应一定数量的请求。
我们需要考虑限制发起请求的数量,或者限制并发响应的数量。这就是rate limiting发挥作用的地方。如果没有rate limiting,很容易会把资源耗尽,或者完全的让系统崩溃,让系统不能响应未来的任何请求。这经常是DDOS攻击的常见做法。
每个人都听说过,使用过或者实现过一些类型的rate limiting。这里有很多不同的算法,其中一种是Leaky Bucket 算法,我们不会在这里展开,但值得一读。
我们可以使用Micro Wrapper和已经存在的库来使用这个函数,一个已经存在的库在这里。
我们实际上对YouTube实现的Doorman算法很感兴趣,一个全局的客户端rate limiter,我们也在寻求社区的其他实现。
前面介绍了很多客户端的很多特性和使用方式,那么服务端呢,第一件事需要注意的是Micro在go-micro的API、CLI、Sidecar等等都使用了客户端,客户端的特性让整个架构都收益,但我们仍然需要在服务端解决一些问题。
在客户端,register用于发现服务,服务端进行注册。当一个服务的实例运行起来时,它在服务发现系统进行注册,在退出时进行注销,关键词是『gracefully』。

在分布式环境中,我们都需要处理错误,我们需要容忍错误。register支持通过ttl来进行过期检查,一旦过期节点就是不健康的,底层的服务发现机制类型consul都支持这些功能。同时服务端也支持重新注册。这两者的结合意味着,节点可以在间隔时间内会重新注册,如果节点因为运行失败等等没有重新注册,register就会因为超时而认为节点不健康,将节点从register删除。
这种容错设计最先没有出现在go-micro中,但我们很快发现,在真实的世界中,因为服务的崩溃或其他原因程序退出时,并没有注销自己,所以需要这种ttl健康监测。
带来的影响就是,客户端需要处理一系列污染的请求。客户端也需要容错性,我们认为这样的功能设计排除了许多明显的问题。
另一件需要注意的事情是,服务端也提供了能力来使用Wrapper和中间件,这意味着我们也可以做circuit breaking, rate limiting等其他一些特性。
服务端的这个功能故意的设计的简单,但插件化的特性可以让你自由扩展。
大部分我们讨论的都是存在于go-micro库中,这对所有的golang使用者是很好的,但其他人在想,我怎样从这里收益呢。
在最开始,Micro就包含了Sidecar的设计理念,这是一个HTTP的代理,所有的go-micro的功能都内置其中,所以不管你用哪种语言构建你的应用,你都可以收益于我们在上面的讨论。

sidecar的设计模式并不是新东西,NetflixOSS有一个叫做Prana的项目。Buoyant有一个叫Linkerd的项目。
Micro Sidecar使用了默认的go-micro客户端,如果你想使用其他功能,你可以添加参数,很容易的重新编译。我们会想办法在未来简化这个程序。
这里讨论了许多go-micro的包和相关的工具,这些工具是很好的开始,但他们还不够。当你想要运行一个可扩展的、数以百计的微服务,处理数百万请求,仍然有许多问题需要解决。
这是go-platform和platform发挥作用的地方了,micro解决了基础的组件,Platform则更进一步,解决运行可扩展的服务的更多问题。比如认证、分布式trace、同步锁、健康检查等等。
分布式系统需要一系列的工具用于提高容错性,Platform看起来会有帮助。通过提供一个分层的架构,我们可以在原始的核心工具上,构建任何自己需要的功能。
Platform仍然在早期,但Platform会解决大部分公司构建分布式平台时会遇到的问题。
科技在快速的进化,云计算给了我们不受限制的扩展能力。设法与变化保持同步很难,构建一个可扩展的,高容错的系统在今天仍然具有很大的挑战。
但不应该用以前的方式解决问题,作为一个社区,我们可以互相帮助,适应这个新的环境,构建随着不断增长的需求而不断扩张的系统。
Micro在这个过程中看起来提供了一些帮助,通过提供工具,简化了构建和管理分布式系统。希望这个文章能示范我们处理这些问题的方式。
这是一系列介绍Micro框架的文章的第六篇,我将会把作者的博客翻译成中文,推广Micro这个微服务框架。
今天我想聊一下机器人。
现在我知道你在想什么,现在有许多关于机器人的夸张说法。如果你对聊天机器人熟悉的话,你会知道这些都不是什么新说法,事实上最早的历史开始于Eliza。大众对机器人重新开始着迷,是因为我们发现了机器人有更多的功能,而不仅是简单的好玩。同时他们也提醒了我们下一代的人机交互接口会演变成什么样。
从工程师的思维来看,机器人不仅是为了交谈的目的,他们在执行任务的时候,超出想象的好用。大部分的我们已经对ChatOps很熟悉了。Github创造了这个概念,推出了他们的 Hubot,这是一个聊天机器人,可以管理技术上和业务上的操作任务。
看看这篇Jesse Newland的演讲了解更多:ChatOpts at GitHub
Hubot和机器人看起来已经证明了,在技术公司他们是非常有用的,他们在运维和自动化方面成为了好用的助手。现在通过HipChat或者Slack操控机器人来执行任务,而以前我们是手动的执行一些脚本,这明显要强大的多。这对整个团队带来的价值是显而易见的,每个人都能看到你在做的事情,已经事情的结果。
Micro,这个微服务工具箱,包括了一系列的服务,提供了接入点连接你正在运行的系统。API,Web控制台,CLI等等。他们都能与你的服务进行交互,观察你的服务的运行环境。在过去的几个月,这已经变得很清楚了,机器人是另外一种接入点,用于与你的服务进行交互与观察你的服务,这也是Micro世界的第一等公民。
这样一来

首先我们要明确,Micro 机器人是处于非常早期的阶段,目前主要是通过CLI提供功能。我们现在不能说实现了ChatOps,但或许有一天可以呢…
Micro机器人包括了类似hubot的语法命令,已经一种实现的输入,比如Slack或者HipChat。这是粗糙的第一个版本,但我相信随着工作的投入,不久以后就能大大提供机器人的能力。希望社区也能加入进来。
Bot 包括了所有的CLI命令,也提供了Slack和HipChat的入口。我们的机器人目前运行在一个demo环境中,通过Micro Slack提供,在这里加入我们。
在最近的开发周期中,我们会看看增加一些入口,比如IRC,XMPP,让我们可以通过命令简单的管理运行中的微服务。如果你有新的入口或者命令需要添加,请提交PR,贡献者是非常欢迎的。目前的插件可以在这里看到:github.com/micro/go-plugins/bot
这确实是一个基础的框架,用于对Micro生态系统做可编程的机器人。整个工具箱拥有插件化的特性。让我们看看Inputs和Commands是怎样工作的。
Inputs是micro机器人怎样连接hipchat,slack,irc,xmpp等等。我们目前已经实现了HipChat和Slack,应该覆盖了大部分的用户。
这里是Input的接口定义
1 | type Input interface { |
Input提供了方便的功能,用于添加你自己的命令行参数。Flag()这个方法会在初始化之前调用,任何自定义的参数会增加到全局参数列表里面。
在参数被解析之后,Init()会被调用,这样一来,这个入口的任何中间数据都会被初始化,一旦所有事情执行完成,机器人就会调用Start()然后是Stream()方法,用于与Input建立连接。
这是Stream方法返回的Conn接口
1 | type Conn interface { |
机器人会持续的调用Recv()来监听事件。Recv()应该是一个阻塞的调用,否则我们会陷入死循环,耗尽CPU。一旦机器人处理完了事件,它会通过Send()返回一些结果。
Event是一个基础的类型,用户在机器人和入口之间通信。他可以让我们把不同的消息类型,封装成统一的格式。目前只有一个TextEvent类型,在未来我们会有更多。
机器人是不知道命令是来自于Slack,HipChat还是其他地方。它只知道收到了一个事件,然后需要执行它。这是一种很好的方式,用于把机器人和Input拆分开。
这里是Event类型
1 | type Event struct { |
commands是可以被机器人执行的函数。这很简单,它们存储在map中,key经过正则,它们会匹配上input接收到的事件。如果正则匹配上了某个事件,关联的函数就会被执行。命令的执行结果就会被发送回input。如果事件的From字段不为空,返回会被发送到To字段。你可以看到这是怎样让机器人直接的进行交流,不管任何地方,任何时候。
当前的Command的接口非常直接,但未来可能会更改,一旦我们遇到更复杂的情况。
command的接口:
1 | type Command interface { |
这里是一个Echo Command的示例
1 | // Echo returns the same message |
只有Inputs和Commands是不够的。如果我们以后想要做些其他的操作呢?我们怎样持久化机器人的状态?双向的交流怎么样?而不是仅仅返回内容。
这必须要编译!
我们仍然处于构建这个机器人框架的早期,这是一个机会,讨论基础的接口应该是什么样的。
下一步是提供各种类型的接口。更严肃一点,我们需要一个Stream接口或者类似的。还需要Input.Conn,这样我们可以处理任何插件的事件流。
这潜在的让我们有能力实现同一时间接收多个input的事件流,因此我们可以从事件流中获取事件,处理后返回。
一个例子是,从Slack中接受到消息,查询micro的服务,最后发送一个总结性的邮件。
micro机器人在你的环境中单独运行起来,就像其他某个服务一样。也会通过服务发现进行注册。
因为机器人就像运行一个其他服务一下,你首先需要启动服务发现机制,默认是consul
使用支持Slack的机器人
1 | micro bot --inputs=slack --slack_token=SLACK_TOKEN |
以及HipChat
1 | micro bot --inputs=hipchat --hipchat_username=XMPP_USERNAME --hipchat_password=XMPP_PASSWORD |
这里有一些运行起来的机器人的截图,就像你看到的,它是一个CLI命令的复制。我们有一些额外的命令比如动画和地图。在这里可以看到github.com/micro/go-plugins

Commands是一个可以被机器人执行的函数,通过字符进行匹配,类似其他的机器人比如Hubot
这里是怎样写一个简单的ping命令
首先通过NewCommand创建一个命令,这个一个快速的方式,你也可以实现这个接口。
1 | import "github.com/micro/micro/bot/command" |
把命令添加到Commands map中,匹配的key需要被golang/regexp.Match匹配。
这里我们只对ping命令作出响应
1 | import "github.com/micro/micro/bot/command" |
在这里引入你的命令
1 | import _ "path/to/import" |
接下来进行编译
1 | cd github.com/micro/micro |
我们要意识到微服务世界并不容易,它需要一系列的工具,还要进行观测。比如监控服务、分布式tracing、结构化日志,这都是重要的组成部分。
想象一个世界,机器人有能力感知分布式系统。当我们需要的时候,提供反馈给我们,而不是需要盯着控制台,处理一个个错误提示。你也许听说过NoOps?那么什么是BotOps?你不会被电话催促怎么样?常见的错误,都通过事先预定的程序处理怎么样?
机器人的革命只是刚刚开始,基础设施和自动化的世界正在改变,我们相信机器人会扮演一个重要的角色,最初是传统的ChatOps ,未来会走的更远。
机器人需要被看做第一等公民,跟配置管理、命令行、和API一样。我们只是把机器人加入到Micro的生态系统中来。
这仍然是处于早期,但不就的将来将会让我们满意。